Method Overview
Starting with multi-view performance data of a subject in a neutral environment, we train a deformable 3DGS to create novel-view renderings of the dynamic sequence. These serve as inputs for a diffusion-based relighting model, trained on paired data to translate flat-lit input images to relit results based on specified lighting. Here, we show the inference step of the diffusion model, where the latent representation of the flat-lit image is concatenated with random noise as input for the diffusion U-Net. Lighting information, encoded as SH encoding together with the text embedding, regulates the diffusion process.

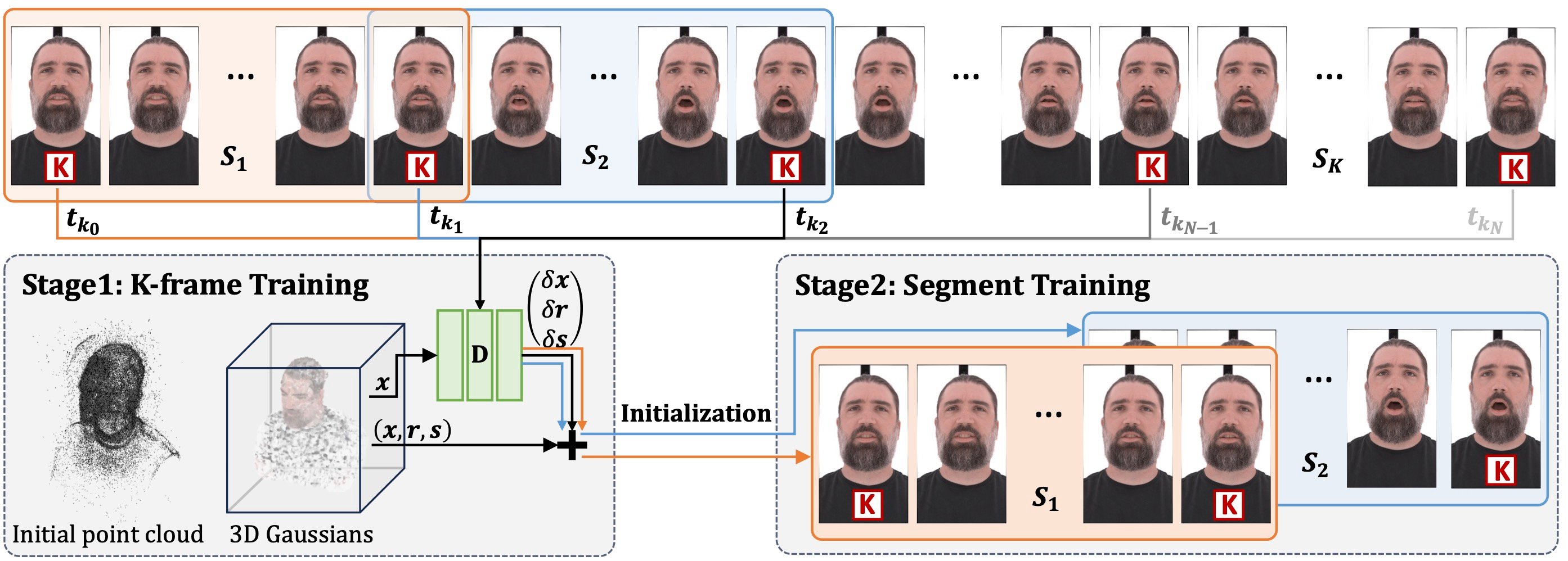
To optimize 3D Gaussians for lengthy performance sequences, instead of training all frames together with one shared set of Gaussians, we partition it into small overlapping segments with an equal number of frames, allowing varying Gaussians across segments. To minimize temporal inconsistency at the transition frames between segments and to preserve a similar level of reconstruction details across segments, we design a two-stage training strategy. We first sample some frames to partition the long sequence into segments. At Stage 1, we train the deformable 3DGS on the starting frames only to generate the initialization for the training of each segment. At Stage 2, we train a deformable 3DGS for each segment conditioned on the initialization. Linear interpolation is used to blend the results of the overlapping segments to ensure temporal consistency on segment transitions.